2 შედეგი · "Inference"
ტექნოლოგია
Tiny-vLLM: შექმენი საკუთარი AI-სერვერი C++ და CUDA-ზე
ახალი პროექტი Tiny-vLLM დეველოპერებს სთავაზობს პრაქტიკულ გზამკვლევს, თუ როგორ შექმნან მაღალი წარმადობის LLM-სერვერი C++ და CUDA ენების გამოყენებით. გაიგეთ, როგორ მუშაობს მოდელები შიგნიდან.
·2 წთ წასაკითხი
ტექნოლოგია
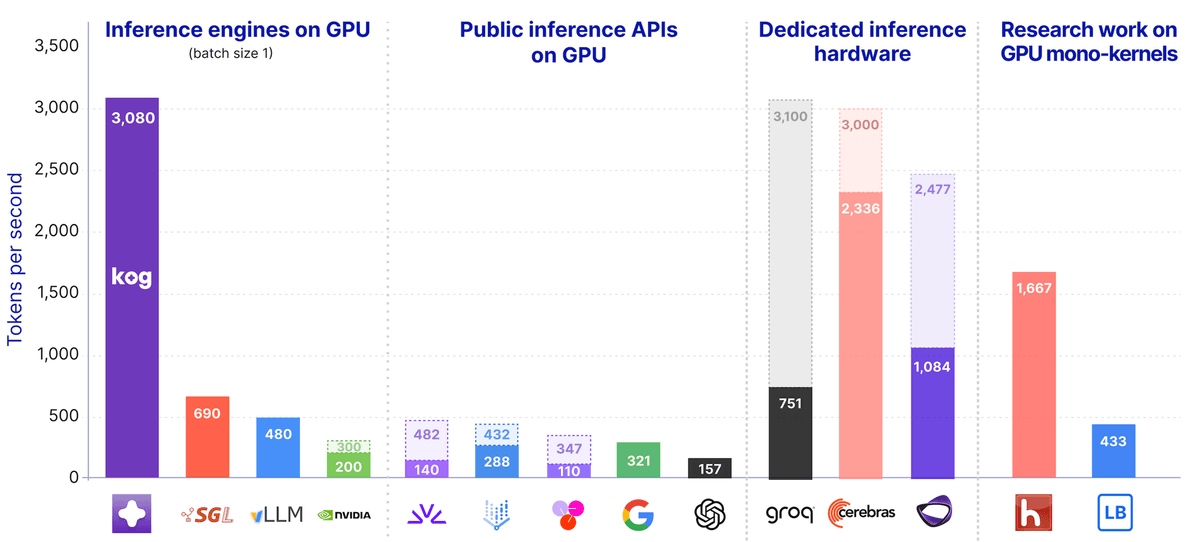
Kog AI-ის ახალი ძრავა: მონაცემთა დამუშავების რეკორდული სიჩქარე
ტექნოლოგიურმა კომპანიამ Kog AI წარმოადგინა ახალი საინჟინრო გადაწყვეტა, რომელიც LLM-ების მუშაობას რადიკალურად აჩქარებს. ინოვაციური ძრავა სტანდარტულ სერვერულ GPU-ებზე სუპერ-სწრაფ გენერირებას ახდენს.
·2 წთ წასაკითხი