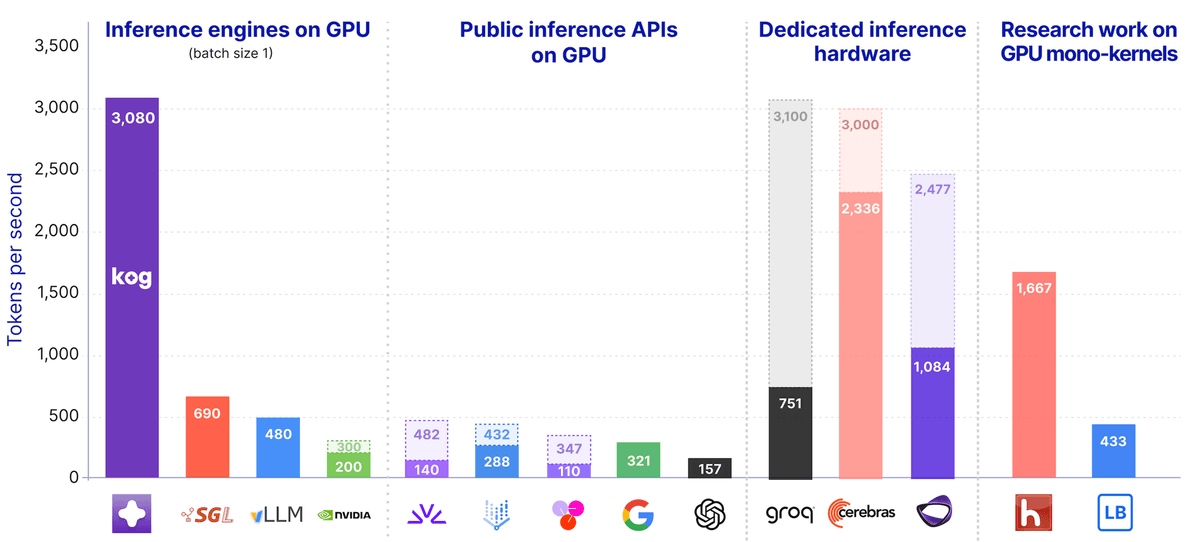
ხელოვნური ინტელექტის განვითარება ახალ ეტაპზე გადადის. კომპანია Kog AI-მ წარადგინა Kog Inference Engine (KIE), რომელიც ენობრივი მოდელების (LLM) მუშაობის სიჩქარეს უპრეცედენტო ნიშნულამდე ზრდის. 8 ერთეული AMD MI300X GPU-ს გამოყენებით, სისტემამ წამში 3 000 ტოკენის გენერირება შეძლო, ხოლო NVIDIA H200-ის ბაზაზე ეს მაჩვენებელი 2 100 ტოკენს შეადგენს.
ეს შედეგი მიღწეულია არა სპეციალიზებული აპარატურის, არამედ პროგრამული უზრუნველყოფის სრული ოპტიმიზაციით. Kog AI-ის გუნდმა შეძლო არქიტექტურის, ძრავისა და დაბალი დონის კოდის ერთიან სისტემად გარდაქმნა. შედეგად, მონაცემთა გადაცემის შეფერხებები მინიმუმამდეა დაყვანილი.
რატომ არის ეს გარღვევა?
ტრადიციულად, ხელოვნური ინტელექტის მოდელების მუშაობის სიჩქარე შეზღუდული იყო არა გამოთვლითი სიმძლავრით (FLOPS), არამედ მეხსიერების გამტარუნარიანობით. Kog AI-მ დაამტკიცა, რომ დაბალი ბაჩინგის (batch size 1) პირობებში მთავარი გამოწვევა მონაცემთა ეფექტური მართვაა.
არსებული პროგრამული სტეკები, როგორიცაა vLLM ან TensorRT-LLM, ორიენტირებულია მაღალ გამტარუნარიანობაზე მრავალმომხმარებლიან რეჟიმში. თუმცა, როდესაც საქმე AI აგენტებს ეხება, რომლებიც მიმდევრობით ასრულებენ დავალებებს, კრიტიკული ხდება ერთი მოთხოვნის დამუშავების სიჩქარე.
AI აგენტების ახალი შესაძლებლობები
- ოპერატიულობა: 50 000 ტოკენის გენერირება, რაც ადრე წუთებს მოითხოვდა, ახლა 20 წამზე ნაკლებ დროში სრულდება.
- ინტერაქცია: აგენტებს შეუძლიათ უფრო მეტი რესურსი დაუთმონ დაგეგმვას, კოდის წერასა და დებაგინგს.
- ავტონომია: პროდუქტიულობის ზრდა პირდაპირ კავშირშია ინტელექტისა და იტერაციის სიჩქარის ნამრავლთან.
Kog AI-ის დამფუძნებლების თქმით, ეს მიდგომა საწარმოებს საშუალებას აძლევს, უკვე არსებული ინფრასტრუქტურით მიაღწიონ ისეთ შედეგებს, რისთვისაც ადრე სპეციალიზებული ჩიპები იყო საჭირო. ტექნოლოგიური პრევიუ უკვე ხელმისაწვდომია დეველოპერებისთვის, რაც საშუალებას იძლევა, რეალურ დროში გამოიცადოს სისტემის შესაძლებლობები.
მომავალი წლისთვის დაგეგმილი ახალი თაობის GPU-ები (Rubin და MI450) კიდევ უფრო გაზრდის მეხსიერების გამტარუნარიანობას. ეს კი საშუალებას მოგვცემს, იგივე სიჩქარე მივიღოთ ბევრად უფრო კომპლექსურ და მასშტაბურ მოდელებზეც.




დისკუსია
0 კომენტარი
ჯერ კომენტარი არ არის — იყავი პირველი.